I may or may not have rage quit at the end of the last post. I had spent so much time debugging and getting it working only to have this one file break everything… again! It was late, I was tired, I was frustrated, and I was already past my self imposed deadline to wrap up for my blog post. I needed to walk away and get some rest and come back with fresh eyes. So here I am 12 hours later, after finally publishing my last post, let’s see if we can get to the bottom of what’s going on with the troublesome PIC file.
I’m officially off schedule now, as my time buffer is gone. The last post came out 12hrs later than I had planned, and this one should have been written by now. Normally My posts were ready almost 24 hrs before being posted. I had hoped to wrap up the PIC file series by today, well at least for the PIC88 version. At which point I planned to move on to a more relaxed posting schedule (2-3 per week). It’s summer now, and I want to spend more time enjoying the weather, instead of at my desk in front of the computer.
Analyzing the outputs
First thing is to take a look at the outputs and see exactly where things are falling apart, and that looks to be much sooner than I had imagined, only 290 bytes into the output. Here we can see (below) our first mismatched byte at 0122 (reference image on the left) Which means the problem is worse than I feared, I guessed it happened at a reset, but this is far too soon for that.

Unlike our earlier problems in the last post, we seem to go completely into the weeds from this point on. From the log below, we can see that we seem to lose it at, a table resize, or shortly thereafter which is really strange.
File: 256REAR.RLE [15377 bytes]
Offset x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 xA xB xC xD xE xF Decoded Text
0000029x: 1F 90 06 03 90 2F 09 90 1E 07 08 00 09 90 12 0B · · · · · / · · · · · · · · · ·
000002Ax: 90 04 09 90 0E 2C 09 90 18 1F 90 04 03 90 9D CE · · · · · , · · · · · · · · · ·
000002Bx: 89 13 07 03 90 80 2D 90 FF 03 90 FF 03 90 81 07 · · · · · · - · · · · · · · · ·
000002Cx: 08 00 09 90 12 C7 2E E0 40 50 1F 16 50 90 0C 88 · · · · · · . · @ P · · P · · ·Nothing odd in the RLE code. This isn’t one of the locations where the reference file has a funky encoding that caused us problems with the RLE encoder. Let’s take another look at the PIC file vs what we output.
File: 256REAR.PIC [7973 bytes]
Offset x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 xA xB xC xD xE xF Decoded Text
0000011x: 16 2C 48 9C 20 20 8C F5 CC 03 BE 48 EC 01 FE 82 · , H · · · · · · H · · · ·
0000012x: A5 89 1D B0 80 7E D6 59 A2 D4 01 01 B5 90 18 08 · · · · · ~ · Y · · · · · · · ·
0000013x: FE 31 17 E0 80 90 B4 E0 98 01 22 55 72 60 40 2C · 1 · · · · · · · · " U r ` @ ,
0000014x: 24 16 42 83 08 24 66 00 84 2C 4C 58 E1 85 90 AC $ · B · · $ f · · , L X · · · ·
File: 256REAR.PIC2 [10213 bytes]
Offset x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 xA xB xC xD xE xF Decoded Text
0000011x: 16 2C 48 9C 20 20 8C F5 CC 03 BE 48 EC 01 FE 82 · , H · · · · · · H · · · ·
0000012x: A5 89 39 C0 02 74 67 39 93 48 6A 01 01 D2 82 44 · · 9 · · t g 9 · H j · · · · D
0000013x: 81 C0 77 8C 0B E0 00 41 92 05 8E 31 80 88 2A 72 · · w · · · · A · · · 1 · · * r
0000014x: C0 00 51 21 62 41 D0 40 04 24 CC 00 C0 00 90 09 · · Q ! b A · @ · $ · · · · · ·I don’t see anything obvious here, going to have to try and look at the data another way. But first I instrumented up our code to create a trace of all the actions, and the relevant states at those points. As we know this is happening at the resize point, I focused in on that first resize in the trace log.
in: 0b / 671 (00029f) [c:1f0 n:1fe r:200]
Searching [1f0:0b]... cE New
Writing [1f0]
out: 01 / 285 (00011d) rem: 6
Adding [1fe = 1f0:0b]
in: 90 / 672 (0002a0) [c:00b n:1ff r:200]
Searching [00b:90]... E New
Writing [00b]
out: fe / 286 (00011e) rem: 7
Adding [1ff = 00b:90]
in: 04 / 673 (0002a1) [c:090 n:200 r:200]
Searching [090:04]... M Exists [14b]
in: 09 / 674 (0002a2) [c:14b n:200 r:200]
Searching [14b:09]... E New
Writing [14b]
out: 82 / 287 (00011f) rem: 8
out: a5 / 288 (000120) rem: 0
FULL! (RESIZE)
***** Table Resize to 10 bits *****
Adding [200 = 14b:09]
in: 90 / 675 (0002a3) [c:009 n:201 r:400]
Searching [009:90]... M Exists [189]
in: 0e / 676 (0002a4) [c:189 n:201 r:400]
Searching [189:0e]... E New
Writing [189]
out: 89 / 289 (000121) rem: 2
Adding [201 = 189:0e]
in: 2c / 677 (0002a5) [c:00e n:202 r:400]
Searching [00e:2c]... E New
Writing [00e]
out: 39 / 290 (000122) rem: 4
Adding [202 = 00e:2c]
in: 09 / 678 (0002a6) [c:02c n:203 r:400]
Searching [02c:09]... E New
Writing [02c]
out: c0 / 291 (000123) rem: 6
Adding [203 = 02c:09]Nothing jumps out as wrong in the flow, or the values. We are going to need to get more invasive now. This is going to hurt me more than you.
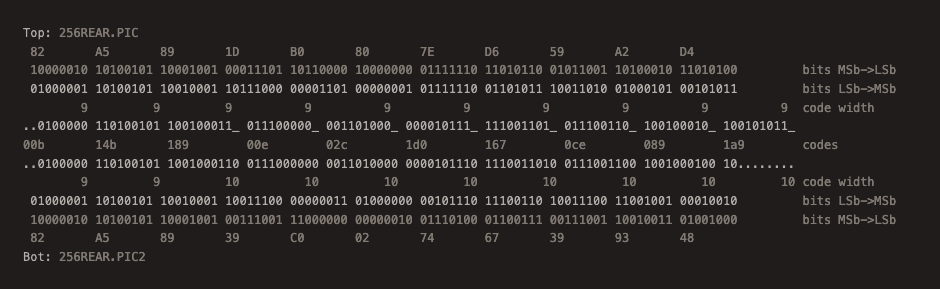
Not gonna lie, this was painful, I think I just lost 2 years of my life. First thing I did was to convert the bytes to bits over a range of +/- 8 bytes from the point where the code size changes, to see if there was any commonality. I could definitely see that we had chunks of the same bits, but it was hard to line things up to any discernible pattern. The problem is looking at it the “normal” way the bits are scrambled a bit due to endianess. So next I took a smaller range, and arranged the bits into the little endian order, so that when we put them into a stream they are properly weighted left to right. (however reverse from what we are used to seeing, in hindsight, I could also have just reversed the order of the bytes and looked at the whole stream from back to front) I was then able to chop the bits up into the code widths according to how our code is outputting them. I then was able to see how the stream from the reference file lines up. Clearly the in the reference file the codes stay at 9 bits at the point where we lose synchronization (after the A5 byte). And given that we cannot cleanly decode what we are outputting, it must be our compressor that is going off the rails and prematurely increasing the code size here. The question still remains as to why. But at least we now know what is happening.
After some thought, the resize mechanism is not the problem here. The problem is that our compressor is generating more codes than the decompressor somehow. Not sure if it’s our hash mechanism that’s failing here or what. I’m hoping that dumping the contents of the hash-table and dictionary at resize will shed some light as to what’s going on here. I may have to do the same on decompression of a good file, and see how the table of entries compares.
Compression Table (9bits)
Dumping String Table:
c:100 p:000 s:03
c:101 p:003 s:90
c:102 p:090 s:ff
c:103 p:0ff s:03
c:104 p:101 s:ff
c:105 p:103 s:90
c:106 p:102 s:03
c:107 p:104 s:03
c:108 p:107 s:90
⋮ ⋮ ⋮
c:189 p:009 s:90
⋮ ⋮ ⋮
c:1ff p:00b s:90Bad Decompression Table (9 bits)
Dumping String Table:
c:100 p:000 s:03
c:101 p:003 s:90
c:102 p:090 s:ff
c:103 p:0ff s:03
c:104 p:101 s:ff
c:105 p:103 s:90
c:106 p:102 s:03
c:107 p:104 s:03
c:108 p:107 s:90
⋮ ⋮ ⋮
c:189 p:009 s:90
⋮ ⋮ ⋮
c:1ff p:00b s:90Good Decompression Table (9 bits)
Dumping String Table:
c:100 p:000 s:03
c:101 p:003 s:90
c:102 p:090 s:ff
c:103 p:0ff s:03
c:104 p:101 s:ff
c:105 p:103 s:90
c:106 p:102 s:03
c:107 p:104 s:03
c:108 p:107 s:90
⋮ ⋮ ⋮
c:189 p:009 s:90
⋮ ⋮ ⋮
c:1ff p:00b s:90Well balls, that was no help, the tables are all the same. Now having said that, we do see at least part of the image, so perhaps we’re fine before the first reset. Which kind of makes sense now that I think about it. It’s after the resize when things change, and if the decoder isn’t ready for it “bad things happen”. So let’s try this again and look at the tables at the second resize.
Compression Table (10 bits)
Dumping String Table:
c:200 p:14b s:09
c:201 p:189 s:0e
c:202 p:00e s:2c
c:203 p:02c s:09
c:204 p:1d0 s:1f
c:205 p:167 s:ce
c:206 p:0ce s:89
c:207 p:089 s:13
c:208 p:1a9 s:03
⋮ ⋮ ⋮
c:3ff p:1da s:c4Bad Decompression Table (10 bits)
Dumping String Table:
c:200 p:14b s:09
c:201 p:189 s:0e
c:202 p:00e s:2c
c:203 p:02c s:09
c:204 p:1d0 s:1f
c:205 p:167 s:ce
c:206 p:0ce s:89
c:207 p:089 s:13
c:208 p:1a9 s:03
⋮ ⋮ ⋮
c:3ff p:1da s:c4Good Decompression Table (10 bits)
Dumping String Table:
c:200 p:14b s:09
c:201 p:189 s:07
c:202 p:007 s:0b
c:203 p:00b s:03
c:204 p:1fa s:50
c:205 p:1d6 s:96
c:206 p:096 s:1f
c:207 p:14a s:07
c:208 p:007 s:03
⋮ ⋮ ⋮
c:3ff p:24c s:0fOkay, we have something, starting at the 2nd entry 201we see a difference between the compressor, and what the decompression of the original PIC file does. Interestingly decompression of our “bad” stream matches exactly with the compressor, yet the image is garbage. So the bad data isn’t bad decoding, its garbage going into the LZW stream. This seems to be reinforced by the fact that at that first entry only the appended character differs. If we were to follow the path back (I included the relevant entry in the 9 bit table) The original PIC file has the string 09 90 07 (repeat 09 7 times) but our version is saying 09 90 0e (repeat 09 14 times). Time to take a closer look at the stack trace again and see what’s happening at that point, and to look at our input file to see what is happening at that position.
Adding [200 = 14b:09]
in: 90 / 675 (0002a3) [c:009 n:201 r:400]
Searching [009:90]... M Exists [189]
in: 0e / 676 (0002a4) [c:189 n:201 r:400]
Searching [189:0e]... E New
Writing [189]
out: 89 / 289 (000121) rem: 2
Adding [201 = 189:0e]
in: 2c / 677 (0002a5) [c:00e n:202 r:400]
Searching [00e:2c]... E New
Writing [00e]
out: 39 / 290 (000122) rem: 4
Adding [202 = 00e:2c]
in: 09 / 678 (0002a6) [c:02c n:203 r:400]
Searching [02c:09]... E New
Writing [02c]
out: c0 / 291 (000123) rem: 6
Adding [203 = 02c:09]Okay we see the same byte we’re writing coming in. What’s in the RLE file?
File: 256REAR.RLE [15377 bytes]
Offset x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 xA xB xC xD xE xF Decoded Text
0000029x: 1F 90 06 03 90 2F 09 90 1E 07 08 00 09 90 12 0B · · · · · / · · · · · · · · · ·
000002Ax: 90 04 09 90 0E 2C 09 90 18 1F 90 04 03 90 9D CE · · · · · , · · · · · · · · · ·
000002Bx: 89 13 07 03 90 80 2D 90 FF 03 90 FF 03 90 81 07 · · · · · · - · · · · · · · · ·
000002Cx: 08 00 09 90 12 C7 2E E0 40 50 1F 16 50 90 0C 88 · · · · · · . · @ P · · P · · ·The data seems to reflect what we’re writing. This is making no sense, time to take a step back and question everything.
Always recheck your data
So I’m an idiot, there is no other explanation. I should have rechecked my files earlier. But it appears that the RLE file I had thought contained the correctly decoded image, actually contained garbage. Running the RLE files down through our individual programs we get the following.


So with that sorted, what does our LZW code do with a good RLE input?

Nailed it! First time!! Ugh… This took far too many hours of wasted effort. I know better, this is so embarrassing. But on the bright side, it works! So now to clean things up and move on. The real lesson here is don’t work while frustrated. Walk away and take a break and come back with a clear head, or mistakes will be made, and repeated.
This post is part of a series of posts surrounding my reverse engineering efforts of the PIC file format that MicroProse used with their games. Specifically F-15 Strike Eagle II (Though I plan to trace the format through other titles to see if and how it changes). To read my other posts on this topic you can use this link to my archive page for the PIC File Format which will contain all my posts to date on the subject.

Leave a comment